Multi-task prompt-RSVQA to explicitly count objects on aerial images
Sep 1, 2023·,, ,,,·
0 min read
,,,·
0 min read
Christel Tartini-Chappuis
Charlotte Sertic
Nicolas Santacroce
Javiera Castillo Navarro
Sylvain Lobry
Bertrand Le Saux
Devis Tuia
Abstract
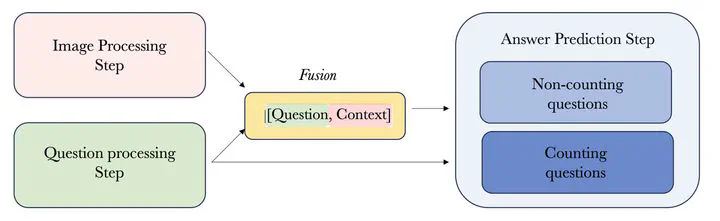
Introduced to enable a wider use of Earth Observation images using natural language, Remote Sensing Visual Question Answering (RSVQA) remains a challenging task, in particular for questions related to counting. To address this specific challenge, we propose a modular Multi-task prompt-RSVQA model based on object detection and question answering modules. By creating a semantic bottleneck describing the image and providing a visual answer, our model allows users to assess the visual grounding of the answer and better interpret the prediction. A set of ablation studies are designed to consider the contributions of different modules and evaluation metrics are discussed for a finer-grained assessment. Experiments demonstrate competitive results against literature baselines and a zero-shot VQA model. In particular, our proposed model predicts answers for numerical Counting questions that are consistently closer in distance to the ground truth.
Type
Publication
British Machine Vision Conference (BMVC) - Machine Vision for Earth observation workshop (MVEO)