Training Visual Language Models with Object Detection: Grounded Change Descriptions in Satellite Images
Jul 1, 2024·, ,,·
0 min read
,,·
0 min read
João Luis Prado
Syrielle Montariol
Javiera Castillo Navarro
Devis Tuia
Antoine Bosselut
Abstract
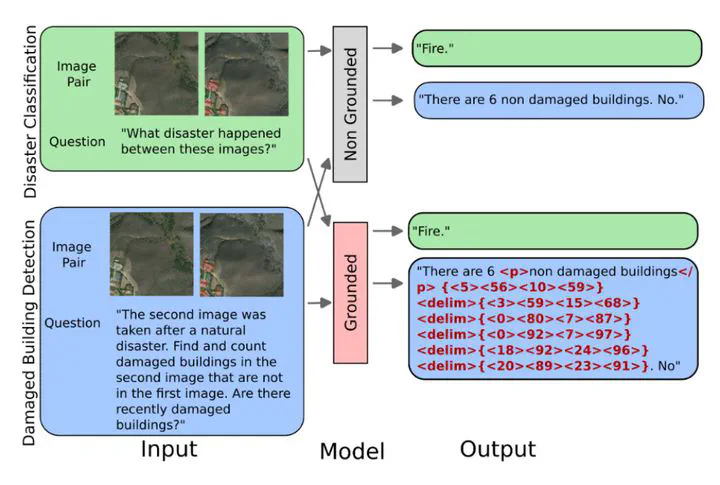
Recently, generalist Vision Language Models (VLMs) have shown exceptional progress in tasks previously dominated by specialized computer vision models. This becomes more prevalent when visual grounding capabilities, such as the ability to reason over input text and image to generate bounding boxes around objects, are required. However, how these capabilities transfer to specialized domains such as remote sensing remains understudied, despite the recent increase in specialized models for Earth observation. In this work, we evaluate how grounding visual entities – by generating bounding-box coordinates – affects VLM performance in satellite imagery. To this end, we create two instruction-following tasks sourced from the xBD dataset, describing changes due to natural disasters observed in satellite images. We fine-tune several instances of MiniGPTv2, an open-source VLM with grounding capabilities, and evaluate their performance under the "grounded" vs. "not grounded" settings. We find that generating bounding boxes to refer to visual entities increases performance in tasks related to objects in the image, but only when the number of entities in the image is limited.
Type
Publication
IEEE International Geoscience and Remote Sensing Symposium (IGARSS)